Liming Kuang, Yordanka Velikova, Mahdi Saleh, Jan‑Nico Zaech, Danda Pani Paudel, Benjamin Busam
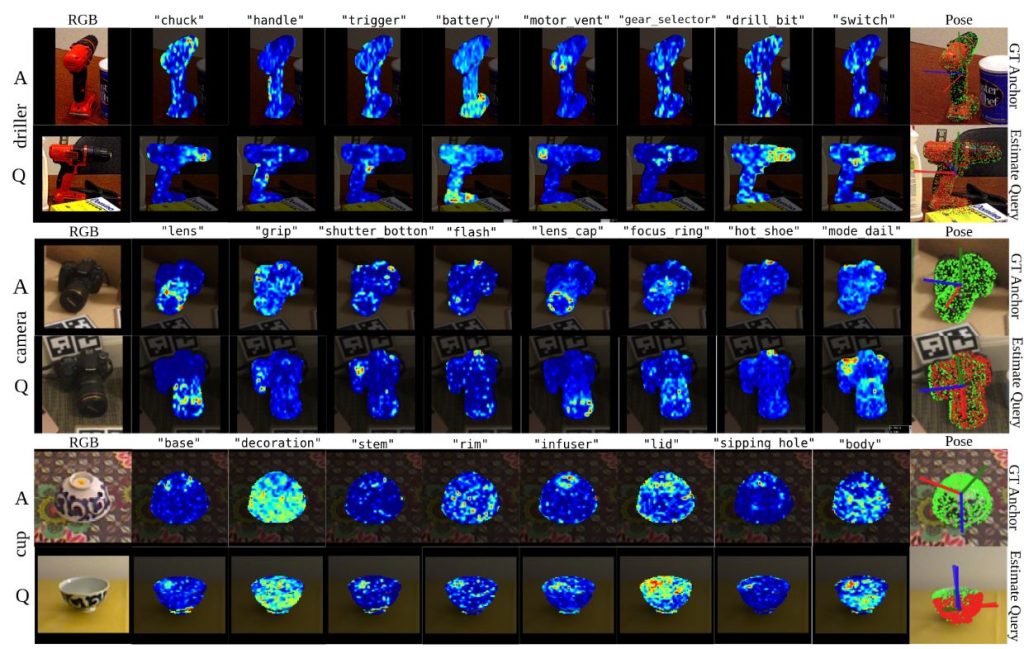
ConceptPose is the first training‑free and model‑free framework for estimating 6‑DoF object poses from images. The method uses off‑the‑shelf vision–language models to extract concept maps from saliency maps. These concept maps provide semantic constraints and guide a differentiable 6‑DoF optimization that does not require any training data. Experiments demonstrate large improvements over prior zero‑shot methods – ConceptPose outperforms the previous best baselines on multiple datasets and brings the ability to handle unseen objects.