Alexander Spiridonov, Jan‑Nico Zaech, Nikolay Nikolov, Luc Van Gool, Danda Pani Paudel
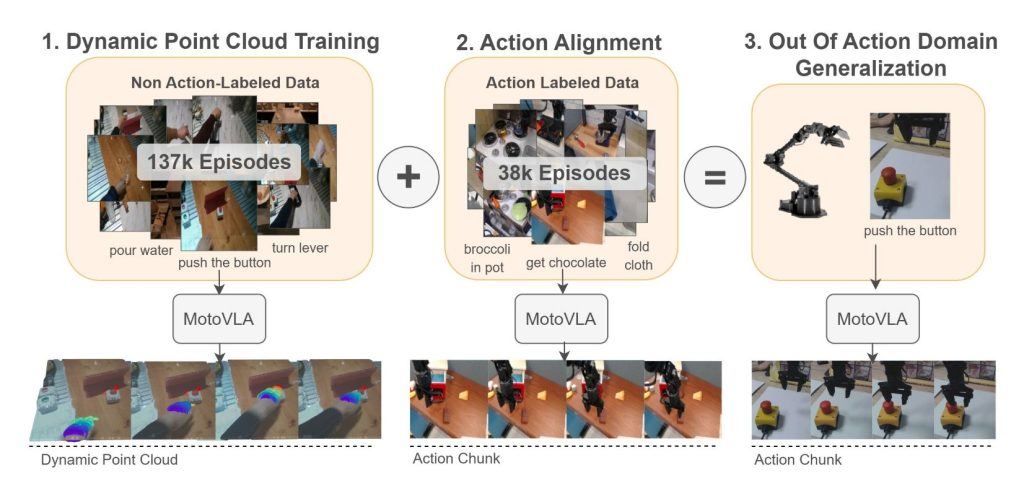
MotoVLA reduces the dependency of generalist robot manipulation on action‑labelled demonstrations. It enables the use of unlabelled human and robot videos to learn object manipulation skills. This is achieved by extracting dense 3D point clouds around the hand or gripper from video data and training a 3D dynamics predictor. The model is then fine‑tuned to predict actions, enabling the robot to learn new tasks without action labels. The method outperforms baselines on multiple manipulation tasks, shows that unlabeled data can significantly improve generalization, and enables a direct transfer form human to robot.
See more demos on our website https://motovla.insait.ai/