3D
-
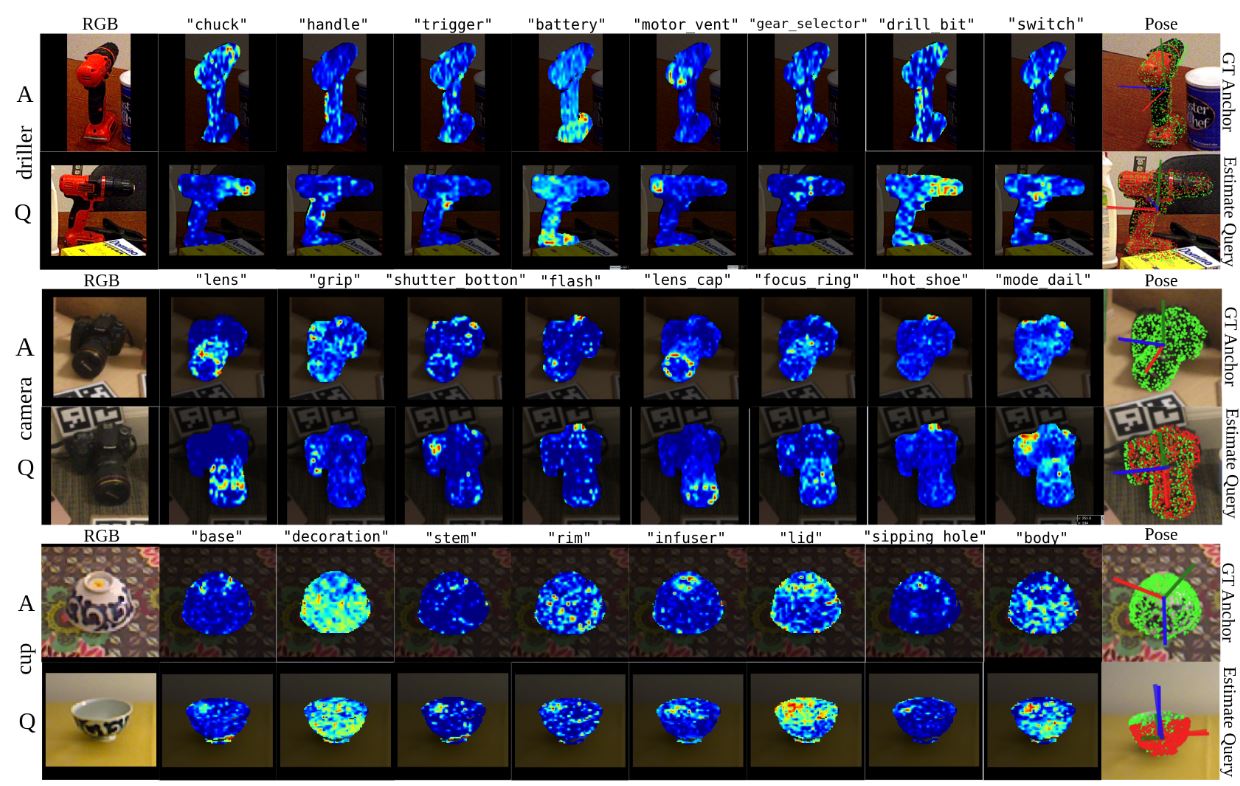
ConceptPose: Training‑Free Zero‑Shot Object Pose Estimation Using Concept Vectors
Liming Kuang, Yordanka Velikova, Mahdi Saleh, Jan‑Nico Zaech, Danda Pani Paudel, Benjamin Busam ConceptPose is the first training‑free and model‑free framework for estimating 6‑DoF object poses from images. The method uses off‑the‑shelf vision–language models to extract concept maps from saliency maps. These concept maps provide semantic constraints and guide a differentiable 6‑DoF optimization that does…
-

Articulate3D accepted at ICCV 2025
Our paper Articulate3D has been accepted at ICCV 2025. The dataset enables high-quality, interaction-aware 3D understanding for embodied AI applications.
-

GaussianVLM: Scene-centric 3D Vision-Language Models using Language-aligned Gaussian Splats for Embodied Reasoning and Beyond
Anna-Maria Halacheva, Jan-Nico Zaech, Xi Wang, Danda Pani Paudel, Luc Van Gool We present GaussianVLM, the first 3D VLM operating on Gaussian splats. Each Gaussian in the scene is enriched with language features, forming a dense, scene-centric representation. A novel dual sparsifier reduces ~40k language-augmented Gaussians to just 132 tokens, retaining task-relevant and location-relevant information.…