Robotics
-
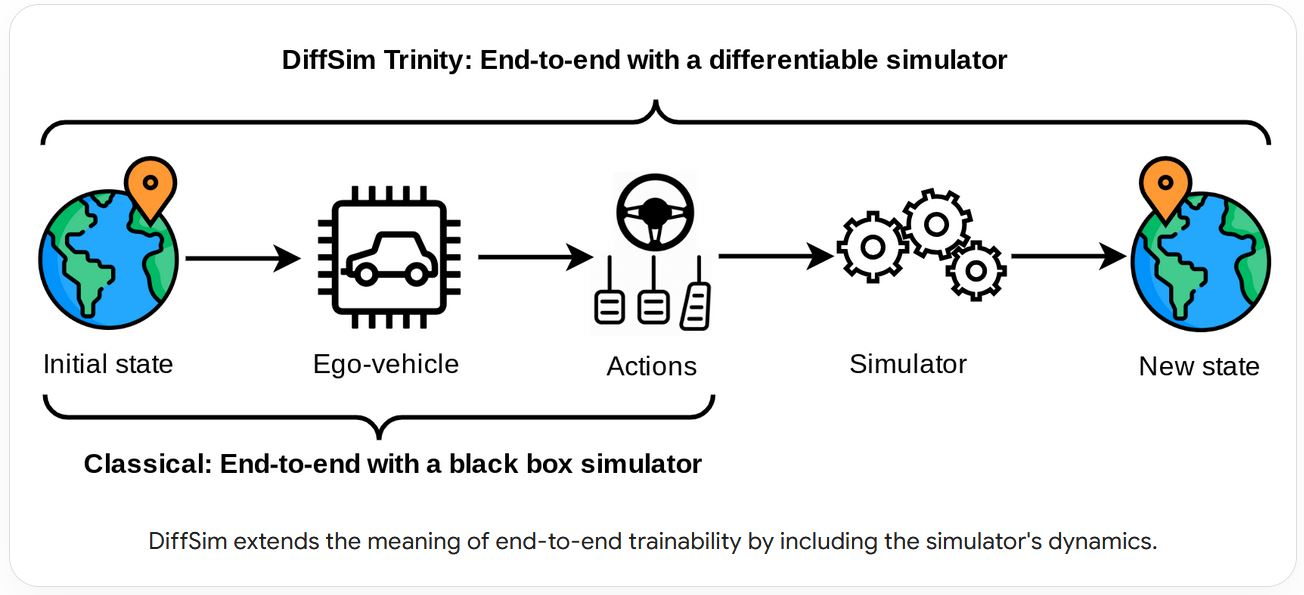
Building The DiffSim Trinity
INSAIT released the DiffSim Trinity, comprising our work on differentiable simulation for autonomous driving.
-
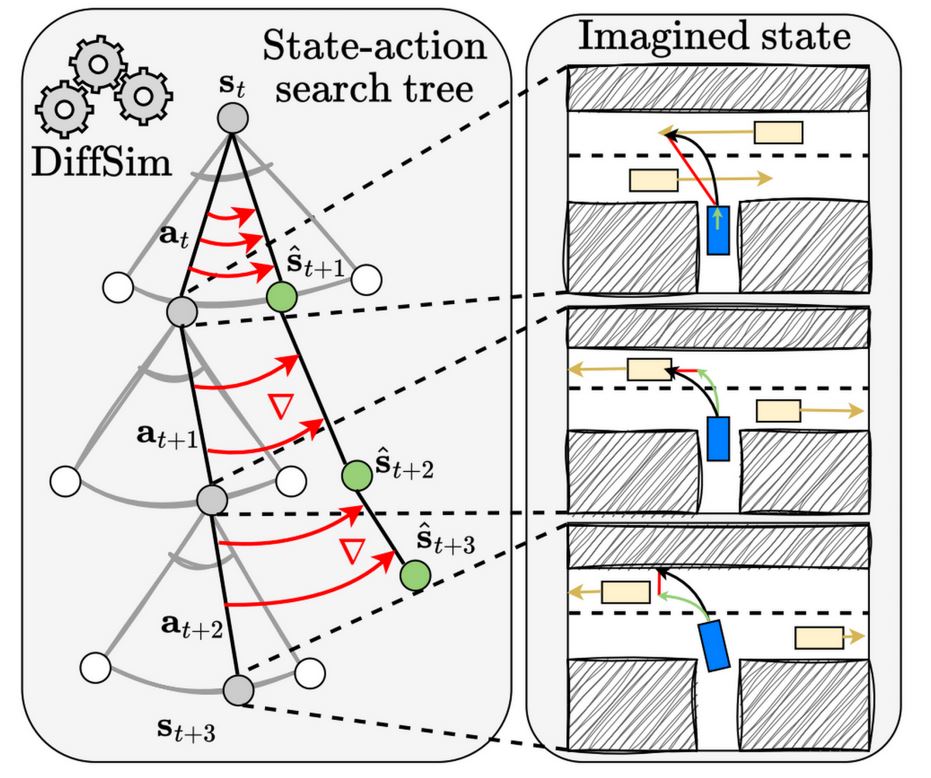
Autonomous Vehicle Path Planning by Searching With Differentiable Simulation
Asen Nachkov, Jan‑Nico Zaech, Danda Pani Paudel, Xi Wang, Luc Van Gool This work introduces Differentiable Simulation for Search (DSS) to address the challenge of planning safe and efficient trajectories for autonomous vehicles. DSS uses a differentiable simulator (Waymax) as both a dynamics model and a critic, enabling gradient‑based search over action sequences. Unlike imitation‑learning…
-
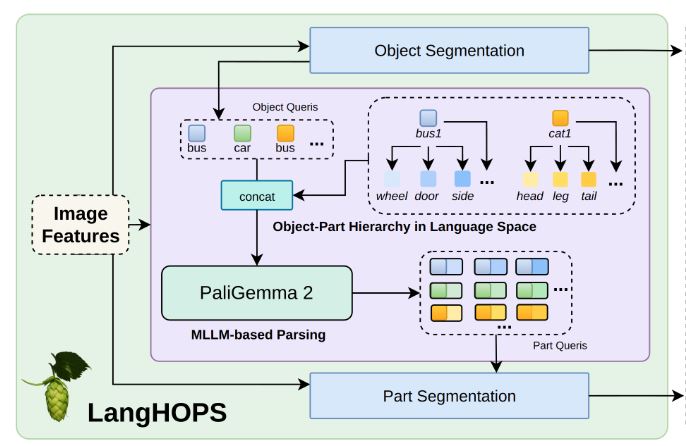
LangHOPS: Language‑Grounded Hierarchical Open‑Vocabulary Part Segmentation
Yang Miao, Jan‑Nico Zaech, Xi Wang, Fabien Despinoy, Danda Pani Paudel, Luc Van Gool LangHOPS introduces a multimodal framework for open‑vocabulary object‑part segmentation. The system models hierarchical part relationships using structured prompts processed with large language models. The approach improves zero‑shot part segmentation performance on PartImageNet and ADE20K benchmarks and achieves better generalization to previously…
-
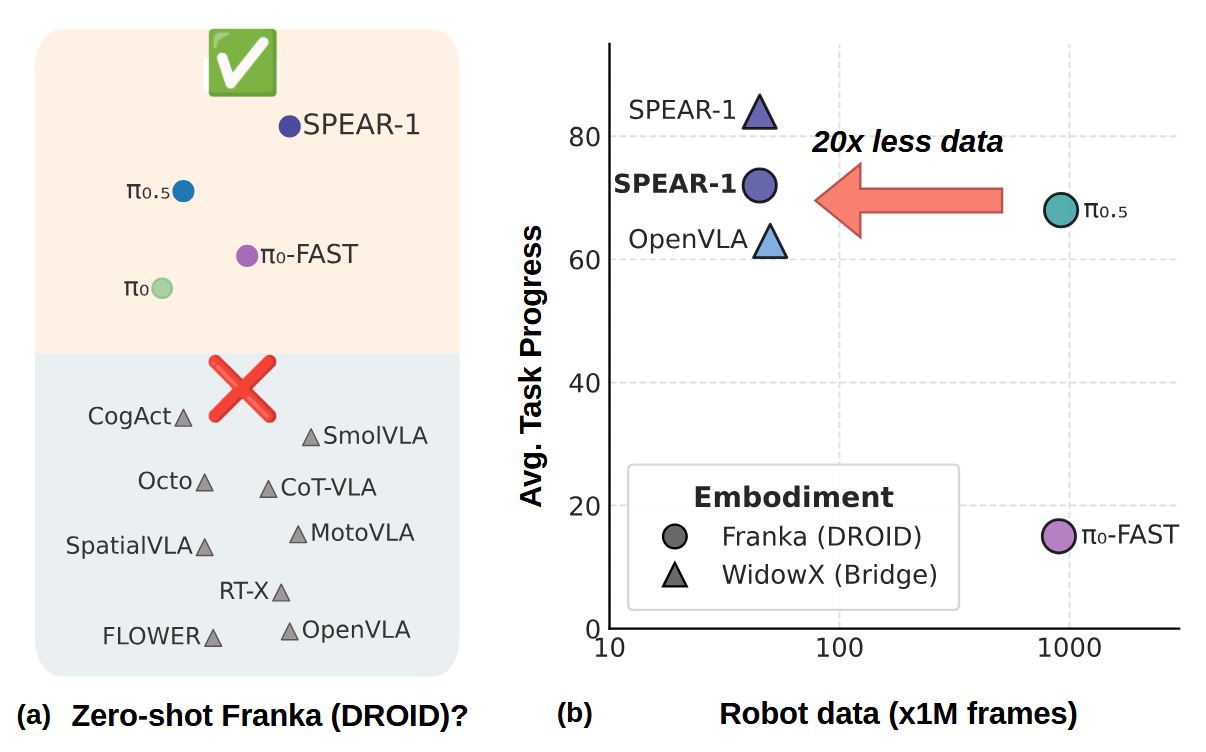
SPEAR-1: Scaling Beyond Robot Demonstrations via 3D Understanding
Nikolay Nikolov, Giuliano Albanese, Sombit Dey, Aleksandar Yanev, Luc Van Gool, Jan-Nico Zaech, Danda Pani Paudel SPEAR‑1 addresses limitations of robot imitation learning by fusing 3D perception with language‑based control. SPEAR-1 introduces a 3D‑aware vision–language model (SPEAR‑VLM) that jointly reasons about 3D scene geometry and human language instructions. This model powers a Vision‑Language-Action Model that…
-
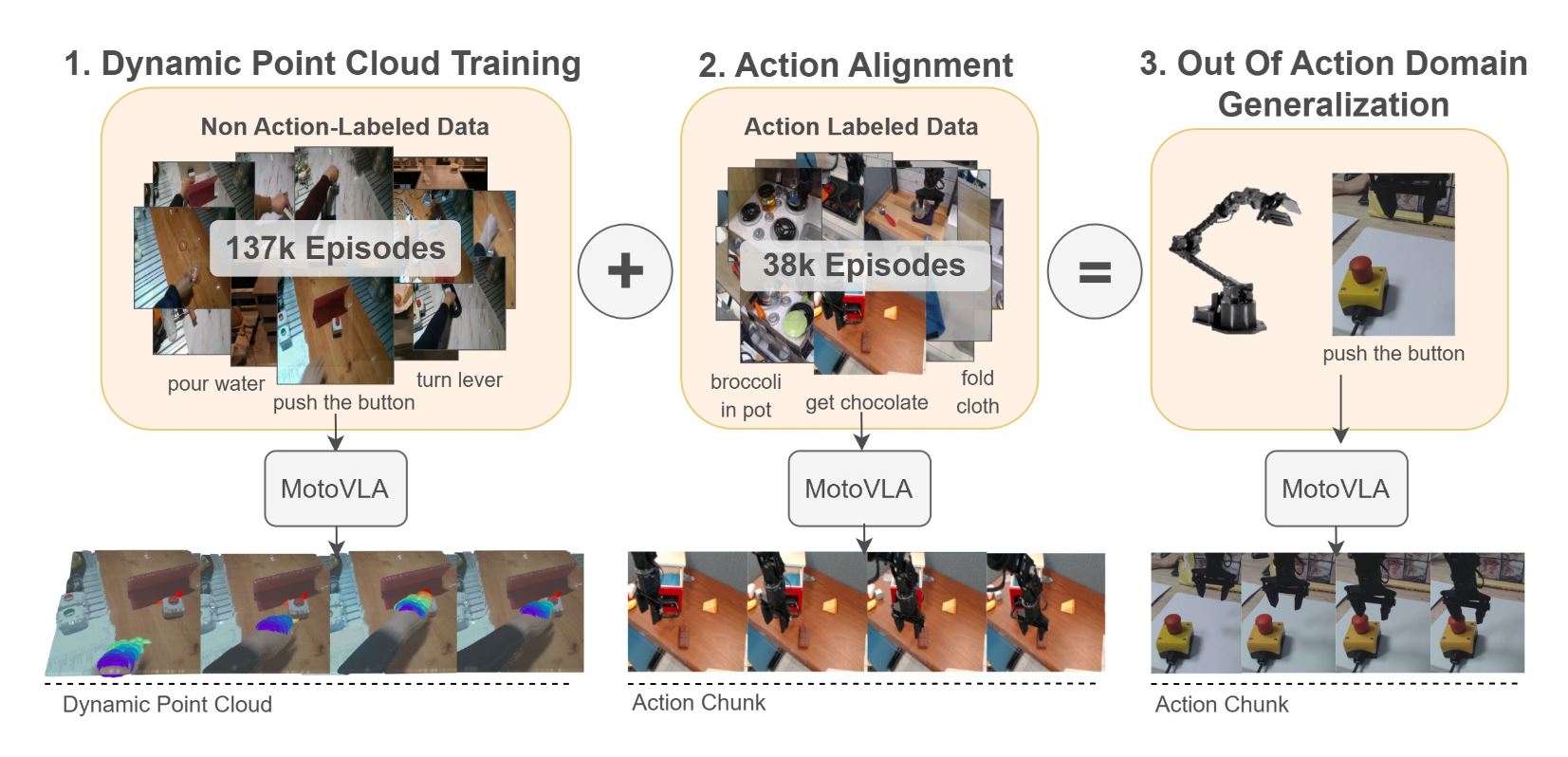
Generalist Robot Manipulation Beyond Action‑Labelled Data
Alexander Spiridonov, Jan‑Nico Zaech, Nikolay Nikolov, Luc Van Gool, Danda Pani Paudel MotoVLA reduces the dependency of generalist robot manipulation on action‑labelled demonstrations. It enables the use of unlabelled human and robot videos to learn object manipulation skills. This is achieved by extracting dense 3D point clouds around the hand or gripper from video data…
-

Articulate3D accepted at ICCV 2025
Our paper Articulate3D has been accepted at ICCV 2025. The dataset enables high-quality, interaction-aware 3D understanding for embodied AI applications.
-

GaussianVLM: Scene-centric 3D Vision-Language Models using Language-aligned Gaussian Splats for Embodied Reasoning and Beyond
Anna-Maria Halacheva, Jan-Nico Zaech, Xi Wang, Danda Pani Paudel, Luc Van Gool We present GaussianVLM, the first 3D VLM operating on Gaussian splats. Each Gaussian in the scene is enriched with language features, forming a dense, scene-centric representation. A novel dual sparsifier reduces ~40k language-augmented Gaussians to just 132 tokens, retaining task-relevant and location-relevant information.…
-

ReVLA@ICRA: Visual Robustness for Robotic Foundation Models
We have presented ReVLA, our first work at ICRA 2025 in Atlanta.
-
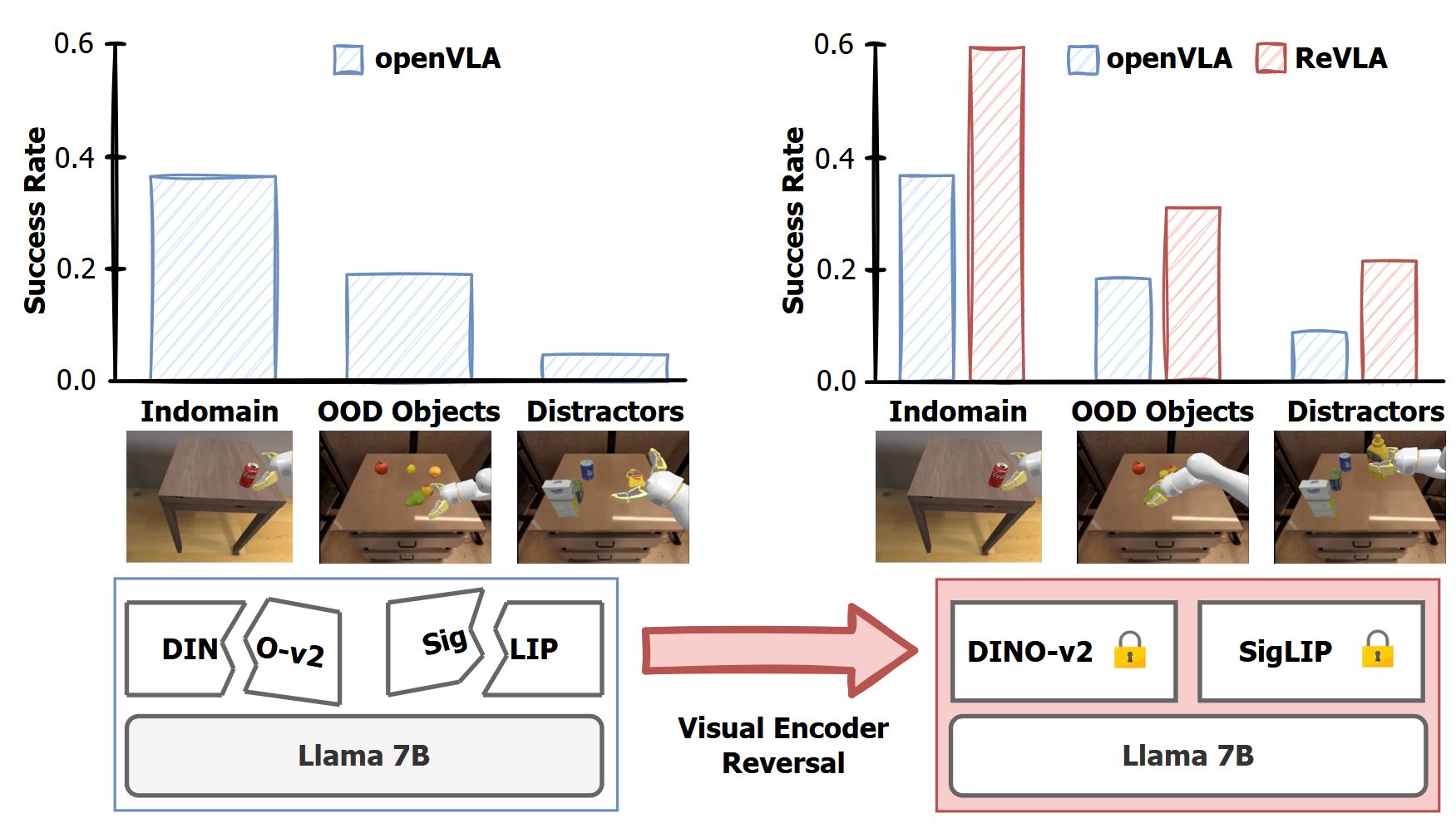
ReVLA: Reverting Visual Domain Limitation of Robotic Foundation Models
Sombit Dey, Jan-Nico Zaech, Nikolay Nikolov, Luc Van Gool, Danda Pani Paudel International Conference on Robotics and Automation, ICRA 2025 Abstract Recent progress in large language models and access to large-scale robotic datasets has sparked a paradigm shift in robotics models transforming them into generalists able to adapt to various tasks, scenes, and robot modalities.…